winterjung blog
하시코프 한국 사용자 모임 밋업 정리
HashiCorp 한국 사용자 모임이 주최하여 2018년 7월 28일 공개SW개발자센터 대강의장에서 있었던 하시코프 한국 사용자 모임 밋업 내용을 정리했다.
밋업소개
- HashiCorp korea user group 소개
- HashiCorp korea 대표
- HashiCorp 서비스 이름 맞추기 퀴즈: 내가 받았다.
- Vagrant, Packer, Consul, Terraform, Vault, Nomad

레거시 위에서 재현 가능한 환경 구축하기 - 권민재
- 발표자 SundayToz, 게임 서버 개발
- 써보고 싶은 사람에게 맞는 내용일듯
- 구성: 기존 문제 - Vagrant - Terraform
기존 개발 환경
- rsync로 배포
- ssh로 들어가서 요청해서 또 rsync
- 계속 ssh로 들어가서 작업, 쌓이는 스크립트, 쌓이는 패키지
- 블랙박스 서버가 됨
문제
- 로컬 디버깅
- 데브 서버는 배포만하고 로컬 서버에서 테스트 하자는 필요
- 구글 드라이브에 돌아다니는 의문의 Vagrant Box
- 당연히 안돌아가고 동일한 환경인지도 모름
- 서버 환경 정의를 코드로 남겨야겠다는 필요를 느낌
- 다중 테스트 서버
- 원래 스테이지 서버에서 하다가 2개 이상의 QA 필요가 생김
- 스위칭 하면서 동시 테스트 -> 실수 유발
- 필요에 따라 찍어낼 수 있는 서버가 필요
- 환경 재현의 어려움
- 라이브에서 광역으로 버그 발생
- 로그로는 알 수 없는 버그
- 라이브 서버 환경을 재현할 방법이 없어 난감
- 급한대로 라이브 서버의 루트 파일 시스템 덤프, 어찌어찌 고치긴함
- 이미지로 서버 프로비저닝이 가능한 환경 필요
- AWS 인프라 이전
- 반드시 동일해야함
- 이왕할거 인프라 자동화를 하자
HashiCorp와의 만남
- Vagrant, Ansible, Packer, Terraform
- 요구사항
- 모든 머신에서 동일한 로컬 프로비저닝 -> Vagrant
- 관리 가능한 인프라 프로비저닝 -> Terraform
Vagrant
- 어려웠던점
- 레거시 코드 추적
- 과연 정말로 배포된 환경과 같을까 확신은 없음
- 로컬 서버 DB 자체 구성
- 나아진점
- 클린 서버
- 로컬 디버깅 수월
- 코드로 남아 추적이 용이
- 새로운 환경 구성 용이
Terraform
- 인프라 정의 파일 작성
terraform plan,terraform apply, 출력값 확인- 리소스간 데이터 참조 가능
- 불필요한 중복 -> Terramform module 활용
- 모듈화 단위는 Network와 Compute로 함
- 정의는 다 됐는데 AMI가 필요함, 그런데 어디서 가져오지?
- 웹에 들어가서 스냅샷 찍어서 빼오기?
- 답은 Packer
- packer build + config.yml -> 인스턴스 생성 -> 프로비저닝 -> 스냅샷 -> AMI 생성 -> AMI ID 출력
- EBS 타입으로 ubuntu 16.04를 베이스로 base.sh를 프로비저닝 한 뒤 출력을 저장하라
- 로컬 서버 구축시 사용한 스크립트와 동일
- jq로 ami를 가져와 terraform 변수로 남김
.tfvars
- 어려웠던점
- 학습 비용: 모듈화 구조잡기 테스트
- Terramform 버그
- 이 방식을 검증해줄 사람이 없음
- 나아진점
- 클린 서버
- 인프라 프로비저닝이 아주 편리해짐
- 코드로 남아 추적이 용이
- 인스턴스 내린 뒤에도 정확히 동일한 환경 구성 가능
- 남아있는 문제
- 아직 로컬 서버의 환경 구성 변경을 즉시 못따라감
- tfstate, tf 데이터 관리
- 프로덕션 서버에는 아직 적용 못해봄, 코드 이전 이슈
- DevOps, IaC 문화
- 서버 프로비저닝과 코드 배포 프로세스의 개선 여지가 많음
마무리
- 최종적으로 프로덕션에서 사용할 수 있을지는 미지수
- 재현 가능 환경은 구성했으나 개선 여지는 많음
- 학습 비용과 구축 비용은 감안
- 정의나 명세 파일의 버전관리가 핵심
QNA
- aws 콘솔보다 코드로 관리하니 효율적이었다
- 패커로 이미지 만들었을 때 이미지 id를 가져오는 방법이 리소스말고 데이터소스로 ami에 대한 데이터소스를 정의하고 필터를 줘서 어느걸 가져올지 줘서 이미지 id 패턴을 지정해 줄 수 있음.
- packer에서 만든 id를 가져올 수 있다는 분에게, 콘솔에서 id를 등록해서 가져오는 방법도 좋지 않을까 고민이 되는 문제
- state 공유하는 문제는 terraform 백엔드가 지원해서 여러 사람 사용할 수 있게 aws s3로 쓸 수 있음
- 코드 배포 프로세스 개선은 ansible을 고려중이나 아직 미정
20명 규모의 팀에서 Vault 사용하기 - 김민규, 김도윤
- 잠시 데브시스터즈 회사소개
- 많은 하시코프 제품 사용/리서치 중
- 그 중에서 Valut를 다뤄보고자 함
< 10명 시절
- 입사자 선물 세트: 공용 비밀번호, 공용 SSH Key
- 서버 100대, 사람 10명 정도가 저 공용 secret을 공유하는 상황
- 어느날 퇴사자 발생 -> key rotate
- 슬랙으로 전달할수도 없고 구전으로 전파함
- ssh 키는 파일만 바꾸면 되는데 그게 100대
- 스크립트 못만들어요?
- aws 계정이 다름
- os가 다름
- 잘못 돌리면 대처하기 골치아픔
- 키 교체 TF 결성
+ 20명
- 서버는 500+대, 사람 20+명, aws 계정 5+개, VPC 10+개
- 찾다가 알아낸게 Vault, 그 중에서 Vault를 통한 SSH 기능
Vault를 통한 SSH
- 간단한 기술적인 설명
- 볼트는 믿을 수 있는 Secret store -> 훌륭한 Certificate Authority 역할 가능
- client가 제가 볼트한테 이런 사람입니다. 접근을 허가해 주세요 하며 public key 보냄.
- 접근을 허가한다. 5분 안에 접속하시오. 서명된 인증서 반환
- 클라이언트는 서버로 제가 접속해도 된대요
- 서버는 인증서가 있으니까 서명된 것이 맞네요. 계속 진행해도 좋습니다.
- 퇴사자가 시도하면 서명은 됐는데 시간이 지나서 안됩니다.
- 초간단 서버 셋업 (볼트가 구성되어있다는 가정하에)
- 인증서를 만든다. 퍼블릭 키만 내려옴
- 접속할 수 있는 인스턴스가 다를 수도 있으니 역할을 등록한다.
- 서버에 인증서 공개키를 등록한다.
- 공용 AMI로 굽는다.
- 클라이언트는 더 간단
vault ssh -mode=ca --role=my-role [email protected]. 앞에 vault만 붙이면 됨 - 새 팀원이 오면 필요한 그룹에 넣어주기만 하면 된다.
- Vault에 장애가 나면?
- 비상용 키 aws 키페어
- 서버들에 기본으로 public key 등록
- 문서화가 잘 되어있음
- 어느날 보면 잘 되어있음
Application에 Secret 넘기기
- 겪고있던 또 다른 문제
- 어떤 식으로든
db_password같은걸 app에 전달해줘야함 - 어떻게 알려주죠?
- 처음엔 Password in Code, 좋은 방법은 아님
- Code의 접근 권한과 Secret의 접근 권한이 다른 경우가 많음
- Rotate하면 코드 싹 다 갈아엎어야
- Github에 저장을 하는데 관리밖에 있는 인프라스트럭쳐임
- AMI에 넣어서 구워두는거도 문제가 많음
- 서버에만 올려두면 오토스케일링 하기 힘듬
- 결국 작업자가 모르는게 최고
- 처음엔 Password in Code, 좋은 방법은 아님
- 그래서 사용한게 Vault KeyValue store
- 권한이 있는 사용자가 볼트에 접근해 요청하면
- 볼트가 값을 내려줌
- Vault는 뭘 믿고 얘한테 키를 줄까
- aws에서 찍어주는 옥새, 인스턴스 자격 증명 문서
- aws에 자격증명서 주세요. 하면 aws가 줌
- 프로비저닝 될때 볼트에 자격 증명 문서를 보냄
- 볼트가 aws와 검증함. 태그, IAM 역할, 메타데이터 받음
- 적합한 토큰 생성해 인스턴스에 반환함
- 쉘로 짜면 2줄정도, Packer로 모든 AMI에 구워넣음
- 3일 전에 Vault Agent 기능이 베타로 출시
- 얘가 지금 말해준 일을 알아서 다 해주는것같음
- aws에서 찍어주는 옥새, 인스턴스 자격 증명 문서
FAQ
- 가로채이면 어쩌지?
- 첫 번째 로그인한 사람만 신뢰, 두 번째부터는 처음때 썼던 nonce값 필요
- 이제는 100% 완벽하고 안전하게 관리하는지?
- 100%는 아니다
- 도커에 환경변수로 전달하는데 그 방법이 안전한건 아님
- 제대로 하려면 각 앱이 Vault API를 호출해야함
- 그래도 예전 코드에 넣거나 작업자가 외워서 사용하는 방식보단 진보함
Vault 구축 과정
- 되게 좋은데 도입을 못하는건 구축 과정이나 사람들의 습관을 바꾸는것 때문이기도
- 만약
- 도입했는데 장애도 많고 불편해요
- 우리 팀은 안쓸래요 뭐가 좋은지 모르겠어요
- 셋업 어려워요 어떻게 써요?
- 하던대로 하면 안돼요?
구축시 신경쓸 점
- 안정성
- 갑작스런 장애는 아무도 원하지 않음
- Vault는 업데이트가 잦다. 무중단 업데이트 가능할 필요성
- 보안
- 절대 털리면 안될 곳이므로 최대한 안전하게
- Vault 권장사항 정독 후 충실히 따름
- 사용성
- 개인적으로 제일 중요하다고 생각
- 사람들의 생활 습관을 최대한 적게 바꾸는 방향으로
- 사람들이 적응하는데 어렵지 않도록
안정성
- 일단 지원되는 건 엄청 많음
- MySQL, Dynamo, FileSystem
- 제일 끌린건 자사제품 Consul
- KV Store, Service Discovery 등
- 뭔가 믿음직함 (중요), HashiCorp Supported
고가용성
- 서버가 두 대면 됨
- Active-Standby, Consul Cluster 3대 -> Vault 2대
- 라우팅을 잘해줘야 하니 ELB를 사용
- 이미 Consul이 훌륭한 Service Discovery 기능 제공
- 유저가 DNS 설정만 잘 해줘도 Vault 알아서 잘 찾음
- 그럼에도 ELB를 선택한 이유
- 테라폼으로 뚝딱 만들면 되니 관리 코스트가 몹시 적음
- 유저에게도 뭔가 시키지 않는 선택지
- 사용성이 좋았다.
- 볼트 클러스터 5대 구성을 테라폼으로 다하고있음
보안
- 볼트에서 시키는거 다 하려면 꽤 피곤함
- 할거면 제대로 해야지 뭐 라는 마인드로 이것저것 다 함
- 제일 힘들었던 건 End-to-End TLS
- 웹 서버 같은 경우는 ELB와 앱 사이는 그냥 HTTP로 하기도 하는데 볼트는 그러지 않길 권장함
- Vault는 기본으로 자체적으로 SSL 서빙이 가능한 상태로
- 인증서, 각각의 인스턴스에서 알아서 발급, 알아서 갱신 -> Let's Encrypt!
- Neilpang/acme.sh 스크립트 사용
- Route53을 활용한 DNS-01 인증
- Audit Logging
- s3에 logrotate로 적재
- syslog도 사용 가능
- ELK같은 로깅 인프라가 있다면 활용 가능
사용성
- 제일 중요한건 문서화라 생각
- 셋업은 한때일 뿐 권한 설정에 더 많은 시간을 쓰게 된다.
- GitHub 그룹 권한 활용, 사내 LDAP
- Secret 관리
- 체계적이고 직관적인 경로 설정, 예
/secret/app/appname/rds - 정책에 관한 꼼꼼한 문서화
- 가급적 도입 전부터
- 체계적이고 직관적인 경로 설정, 예
- 적응에 도움주기
- 개념 자체가 생소하고 어려움
- 기본 개념부터 하나하나 문서화
- 회사 개발팀 돌면서 강의 진행
- 도움되는 스크립트 공유
회고
- 굉장히 편함
예상을 벗어났던 것
- 권장은 권장일 뿐
- End-to-End TLS는 셋업 난이도 수직상승
- Consul
- 은근 관리 까다로움
- 버전업을 한번에 성공한적이 없음
- 적극적인 백업 권장
- 히어로
- 없던 정책을 새로 설정하고 관리하는 건 생각보다 힘든 일
- 의지와 추진력을 가진 자가 필요함
- Case: Unseal
- Vault 인스턴스는 처음 뜨면 봉인된 상태
- n명 중 m명이 모이면 해제할 수 있다
- 7명의 Unsealers를 지정해서 관리 책임을 분산
- 이상은 어벤져스
- 현실은 저스티스리그
- 혼자서는 팀을 구할 수 없다
- 애매하게 분산된 책임
- 결국 운영하는 두 명이 Unseal도 하는 중
- 처음엔 unseal 최저 인원 무조건 낮게 잡는게 좋을 듯
- 인내심
- 기다리던 업데이트도 문제가 생겨 종종 롤백
- 새로 개발되는 기능은 좀 기다렸다 써보자
- 혹은 PR과 이슈
예상보다 더 좋았던 것
- Audit Logging
- 최고의 장점이자 핵심 가치
- 조사하면 정말 뭐든지 다 나온다
- 비밀번호 누가 바꿔놨지 -> 검거
- 세팅이 왜이래 -> 검거
- 일단 넣기 문화
- config 파일 -> KV에 넣어
- 공용 OTP는 -> TOTP Backend
- 그냥 간단히 안전하게 전달하고 싶은데 -> Transit Backend
- 이게 극히 일부만 쓰고 있는 것
- 엄청난 발전 속도
- 없던 UI
- 가이드 문서
- 버저닝
- CLI 자동완성
- 줄줄이 패키지
- 자사 제품과의 연계가 좋음
- Consul, Terraform, Packer, Nomad
- 쿠버네틱스는 볼트랑 같이 쓰기 그리 쉽진 않았음
이런 분들에게 추천
- Terraform 적극 사용 팀
- 보안 스탠다드가 높거나 높이고 싶음 팀
- 급격히 성장중이고 빠르게 인원이 증가하는 팀
- 아니면 데브시스터즈 오세요
Why Terraform, Why not CloudFormation - 신근우
- 대상 청중
- AWS 사용하시는 분들
- Infrastructure as code 를 시작하시려는 분들
- Terraform 도입을 하시려는 분들
클라우드포메이션 얘기
- 문제가 많다
Terraform 얘기
- 다양한 Provider
- AWS, Azure, GCP, K8S, RabbitMQ, Vault 등
- Built-in functions
- State는 Terraform 설정과 Real-world Infrastructure 간의 매핑, 알파이자 오메가라고 생각함
- Data Source / Module / State로 유연하게 Resource 관리 가능
- 단점
- 제대로 롤백이 안될 때가 있음
- 느린 속도때문에 반 강제된 모듈화
- 익숙하지 않은 HCL
- Simple and Powerful
그들이 서비스와 엔터프라이즈 인프라를 AWS 위에서 다루는 방법 - 박훈
- ZEPL, 소프트웨어 엔지니어
- 슬라이드 주소
문제
- 사용자 하나당 컨테이너 하나나 n개 받아갈 수 있음
- 2018년 1월에 k8s 관련해 발표함.
- 주키퍼 카우치DB는 설치해 사용함
- k8s cluster, ecs cluster
- 엔터프라이즈를 위해 복사할 인프라, 제약조건들
- AWS Infra
- 인스턴스를 띄워서 소프트웨어를 깔고 클러스터링
- k8s와 에드온 설치
- 스키마 채워주기
- 앱 설치 + 마이크로서비스
- 모니터링 + 알림
- 로깅
- 엔터프라이즈 고객이 쓰고있는 서비스를 테스트돌릴 수 있어야함
- 엔터프라이즈 특화 문제
- 커스텀, 스케일링, ECR 공유, 깐깐한 인프라 룰, 보안 정책
- Feature Flags/Toggles
- 고객마다 k8s 클러스터가 생기면
- Users X Clusters, 배포방법 알아야함
- Secrets
- 지식 전파
어떻게
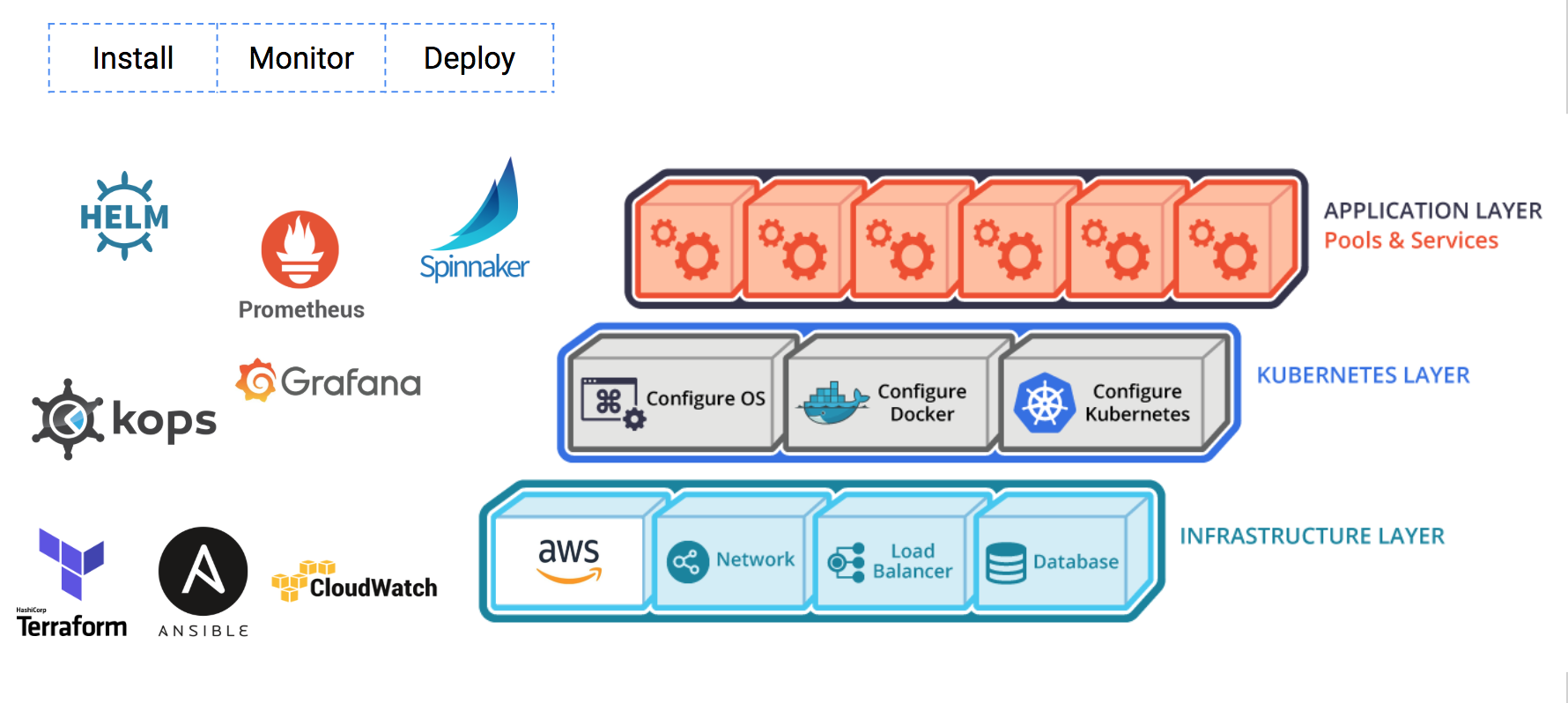
- 인프라 레이어, k8s 레이어, 앱 레이어
- 각 레이어에 인스톨, 모니터, 배포 총 9개
Infra + Install -> Terraform, Ansible
- Generate Template & Execute Task
- 다양한 옵션
Infra + Monitor/Logging -> AWS Cloudwatch & LOG
- EC2 MEM, DISK 기본으로 안줌
- 오토 스케일링 그룹에서 알람 가게하려면 또 복잡함
- ECS 모니터링 하려면 이런거 이런거 하면 됨
- Storage는 메트릭이 더 많음
- 직접 설치한 서비스 EC2, ELB 활용
k8s + Install/Deploy -> kops
- Terraform 으로 만들고 kops replace
App + Install -> HELM
- Flyway
App + Monitor -> Prometheus
- operator
TODO
- App + Deploy -> Spinnaker
Summary
Packer와 Ansible로 AMI 빌드하고 Vagrant로 빌드 과정 검증하기 - nacyot
- 당근마켓 재직, 44bits.io 운영
- 패커와 베이그런트
Packer: 범용 커스텀 이미지 빌드 도구
- 타켓 애플리케이션이 작동하는 균형 상태
- 프로비저닝이 끝난 상태를 이미지로 저장
프로비저닝은 서버 등의 요소를 사용할 수 있는 상태로 만드는 것 - 코드로 인프라 관리하기
- 기존의 이미지 빌드
- 서버 관리자가 서버를 직접 수정하고 그대로 저장
- 처음엔 혁신적인 방법이었음
- 지금은 관리가 어렵고 재현 불가능
- 수동임
- 언제 필요할지 모르는 이전 이미지는 쌓이기만 함
- Build Automated Machine Images
- 패커의 핵심 부분은 빌더와 프로비저너
- 빌더: 특정 플랫폼 이미지 만드는 플러그인
- 프로비저너: 프로비저닝을 수행하는 플러그인 (sh나 chef, ansible등을 사용함)
- e.g. Builder는 Docker, Virtualbox, amazon-ebs 등등
- 이미지 빌드 특징 -> 패커 프로젝트 repo
- 코드로 관리
- 변경 때마다 매번 이미지 새로 빌드
- 재현 가능
- 자동화 가능
- 데모 01 - 패커로 AMI 빌드
- 단점
- 단 한 방에 이루어짐
- 빌드 시간이 김
- 빌드 과정에 개입할 수 없음
- 프로비저닝에서 문제가 생기면 처음부터 다시
Vagrant
- 점진적 이미지 빌드
- 프로바이더 + 프로비저너
- 프로바이더 vs 빌더
- 프로바이더는 아웃풋으로 VM
- 빌더는 아웃풋으로 이미지
- 프로비저너 업데이트 후 provision 명령어로 반영 가능
- 패커는 되기 전까지 될지 안될지 모름
- 베이그런트로 개선 가능
- vagrant up -> vagrant provision -> 에러가 나면 다시 고치고 -> vagrant provision (이 때 ansible 같은 경우 성공한 부분은 넘어가기 때문에 이 개선이 빠르게 이루어짐)
- 가상 머신과 패커 빌드 환경은 다르다 -> vagrant-aws 라는 프로바이더 사용 가능
- VM 대신 AWS 인스턴스 실행
- 키페어 지정 부분만 다르고 거의 똑같음
- 데모 02 - Vagrant aws
- 함정
- destroy 안하면 인스턴스 계속 남아있음
- 미묘하게 패커 빌드 환경과 다를 수 있음
- 프로비저닝을 하다 보면 달라질 수 있어서 destroy 후 up 을 통해 검증
결론
- 패커로 이미지 빌드 자동화
- 베이그런트를 통해 이미지 빌드 과정을 사전에 검증
- 급할수록 돌아가자
개인적인 후기
- 작은 부분부터 Terraform으로 바꿔보자.
- 데브시스터즈 발표 재밌다.
- NDC에서 듀랑고팀도 Packer와 Ansible 얘기하던데 슬라이드 다시 봐야겠다.
- 서버로 SSH 접속해 업데이트하는 배포에서 벗어나자.